Die Seitenleiste
Vor ungefähr 5-10 Jahren (2004), war die Desktopsuche auf Windows XP und Windows 2000 noch nicht so gut wie heute. Man konnte zwar nach Dateien suchen, jedoch wurde der Computer ausschließlich nach Dateinamen durchsucht und nicht auch nach den Inhalt.
Um dies zu ermöglichen waren Tools von Drittanbietern notwendig. Google hatte eine eigene Software erstellt und diese „Google Desktop Search“ getauft.
Damit war es möglich, einfach im Browser die Suchwörter einzugeben und schon konnte der lokale Computer und auch das Netzwerk durchsucht werden.
Später gab es dann sogar noch eine Linux Version.
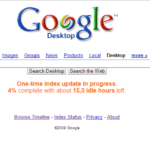 Wenn man wollte, so konnte man auch die Seitenleiste einblenden, die zusätzlich interessante Informationen, wie Wetter, News, oder zB RSS-Feeds anzeigte.
Wenn man wollte, so konnte man auch die Seitenleiste einblenden, die zusätzlich interessante Informationen, wie Wetter, News, oder zB RSS-Feeds anzeigte.
Im Jahr 2011 wurde die Google Desktop Suche jedoch eingestellt, da laut Google, immer mehr Leute die Cloud verwendeten und dort ihre Files durchsuchten (zB Google Drive).
Alternativen
Es gibt zwar Alternativen, wie zB Lookeen, oder Copernic, die beide durchaus gut sind,jedoch vermisse ich hier die Suchmöglichkeit im Browser.
Funktioniert Google Desktop Search noch auf Windows 10?
Sagen wir so: Jein…
Die Desktopsuche und das indexieren von Dateien funktioniert noch (über Umwege die man einmal einrichten muss), aber die weiteren Features (zB die Seitenleisten, oder die Möglichkeit per Tastendruck den Computer zu durchsuchen, egal, ob man sich gerade im Browser befindet, oder nicht) funktionieren leider nicht mehr unter Windows 10.
Wem die reine Dateiensuche im Browser ausreicht, dem wird auch die eingeschränkte Google Desktop Suche (GDS) ausreichen.
Im Anhang an diesen Beitrag, befindet sich die Installationsdatei von GDS (auf Englisch und Deutsch).
Wenn man diese installiert hat, dann wird einem vermutlich gleich einmal die Seitenleiste auffallen, jedoch kann man mit der Seitenleiste nicht viel anfangen, da gewisse Optionen und weitere Features einfach nicht reagieren. Macht nichts, wir schalten es gleich ab.
Normalerweise konnte man früher die Desktop Suche entweder über die Tastenkombination „STRG+STRG“ (zwei mal hintereinander drücken), oder über die URL desktop.google.com erreichen.
Beide Wege scheiden hier aus, aber wie erreichen wir nun unsere Desktop Suche?
Registry durchsuchen
NACHDEM Google Desktop Search installiert wurde (Download ganz unten), müssen wir etwas in der Windows-Registry suchen
Keine Sorge wir ändern hier nichts, sondern wir lesen nur etwas aus!
Wenn du in den Registry Editor gehst (in der Windows-eigenen Suchleiste „regedit“ eingeben) und dort nach den Schlüssel „search_url“ unter HKEY_CURRENT_USERSoftwareGoogleGoogle DesktopAPI suchen:
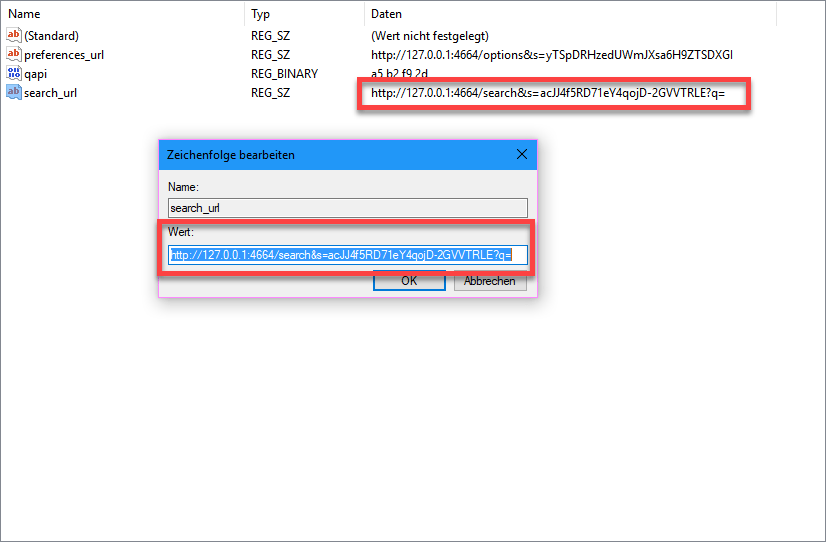
Diesen Wert einfach nur kopieren und im Browser eingeben, das ist die URL über die die Google Desktop Suche erreichbar ist. Diese URL am Besten gleich mal in den Favoriten/Bookmarks abspeichern, damit du die GDS schneller erreichen kannst.
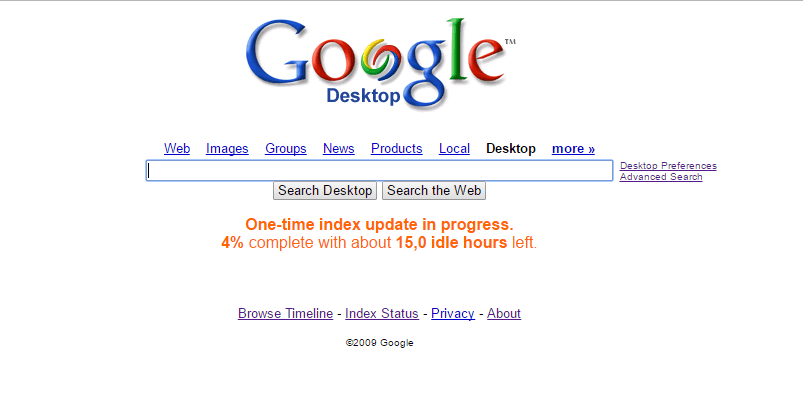
Grundeinstellungen
Wenn wir die Suchseite aufrufen, dann sollten wir uns als erstes die Einstellungen („Desktop Preferences„) ansehen.
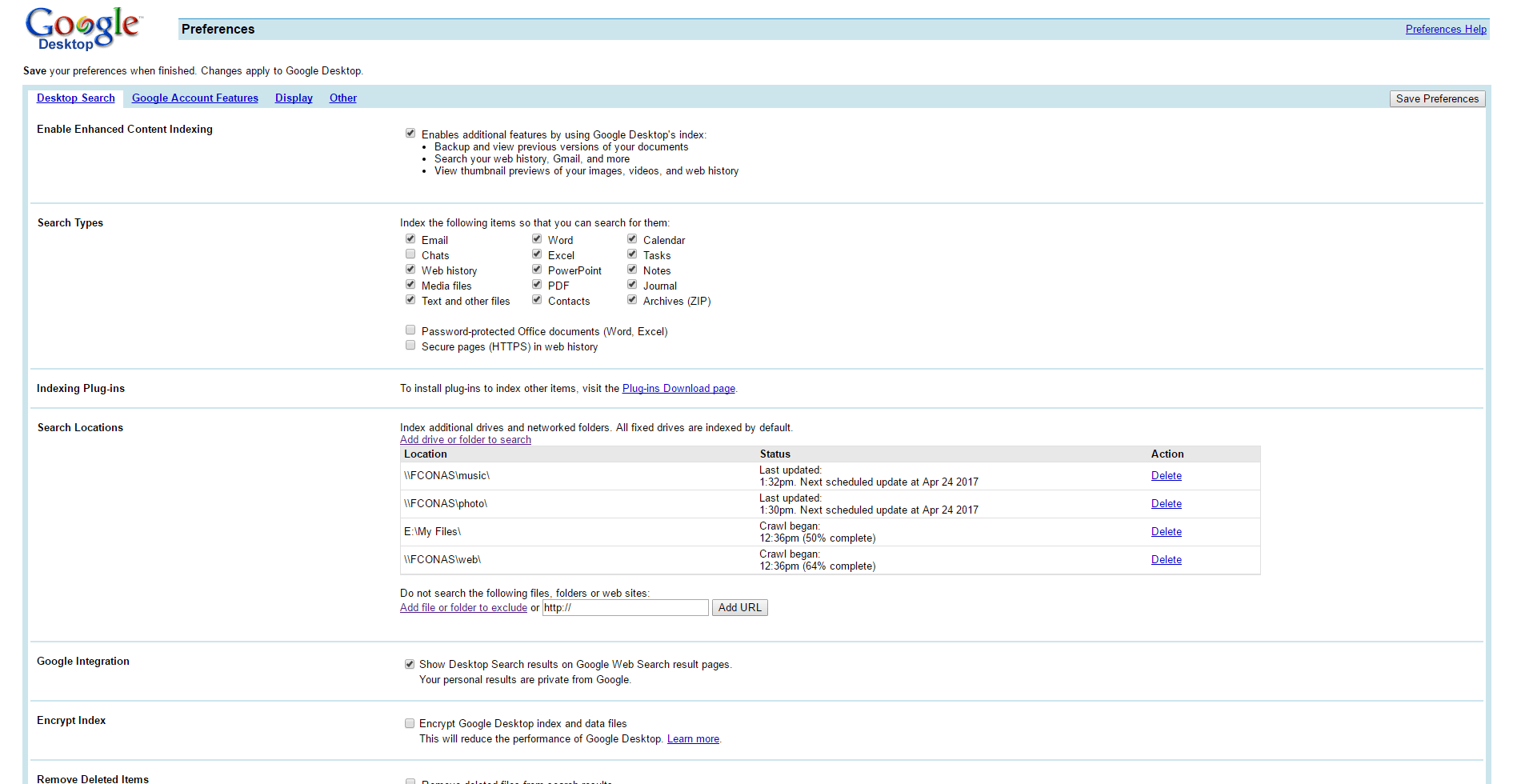
In den Einstellungen unter Desktop Search ist wohl mal das wichtigste, WAS denn überhaupt durchsucht werden soll.
Bei Search Types ist so ziemlich alles ausgewählt. Wobei hier nicht mehr alles funktioniert. Zum Beispiel bin ich mir bei „Email“ nicht sicher, ob er hier auch die heutigen Versionen von E-Mail Clients wie zB „Thunderbird“ und „Outlook“ noch durchsucht. Da ich (und vermutlich viele andere auch) die E-Mails über den Browser lesen/schreiben, konnte ich dieses nicht ausführlich testen.
Der Zweite Teil den wir auf dieser Seite einrichten wollen sind die Search Locations. Hier kann man eigene Ordner und auch Netzwerklaufwerke hinzufügen, diese können nach der Indexierung dann durchsucht werden.
Anschließend speichern nicht vergessen.

Mit diesen Feature unter „Google Account Features“ konnte man sein Google Konto integrieren, somit war die Gmail Suche auch in GDS möglich. Dieses Feature funktioniert inzwischen aber nicht mehr, da Google in der Zwischenzeit auch die Methode der Authentifizierung geändert hat.
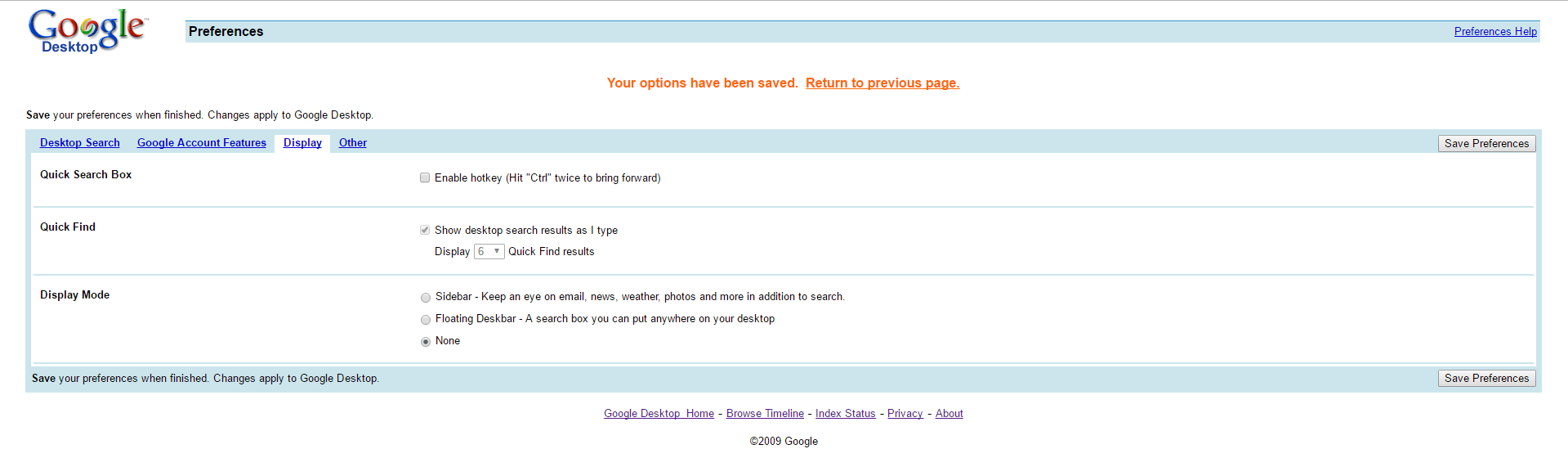
Hier kommen wir zur Seitenleiste. Vermutlich sind diese hier aktiviert.
Die „Quick Search Box„, die mit Doppeltippen der STRG-Taste erreichbar ist, funktioniert ja sowieso nicht einwandfrei, deswegen kann man das Feature hier auch deaktivieren.
Den „Display Mode“ kann man auch „None“ einstellen, damit wird die Seitenleiste deaktiviert, da diese sowieso nur eingeschränkt funktioniert.
Speichern nicht vergessen.

Auch das wird keine Funktion mehr haben, da Google den Support dafür 2011 eingestellt hat.
ABER sollten sie doch noch Crash Reports erhalten, dann hab ich nichts dagegen wenn sie diese auch erhalten. Vielleicht beleben sie Google Desktop Search dann wieder, wenn es mehrere Leute machen.
Einstellungen im Browser
Gut, wir haben nun GDS soweit einmal eingerichtet. Im Moment wird bei der Suche vermutlich noch nicht viel gefunden werden. Keine Sorge, GDS indexiert die Dateien während der Computer gerade nicht verwendet wird (sprich: Während du gerade Kaffee holst, oder auf’s Klo gehst). Beim ersten Einrichten kann es außerdem eine Weil dauern, das ist normal. Den Aktuellen Status siehst du unter anderem, wenn du auf „Index Status“ klickst. Nicht erschrecken, wenn da zB „15 Stunden“ steht. Es dauert nämlich nicht so lange…
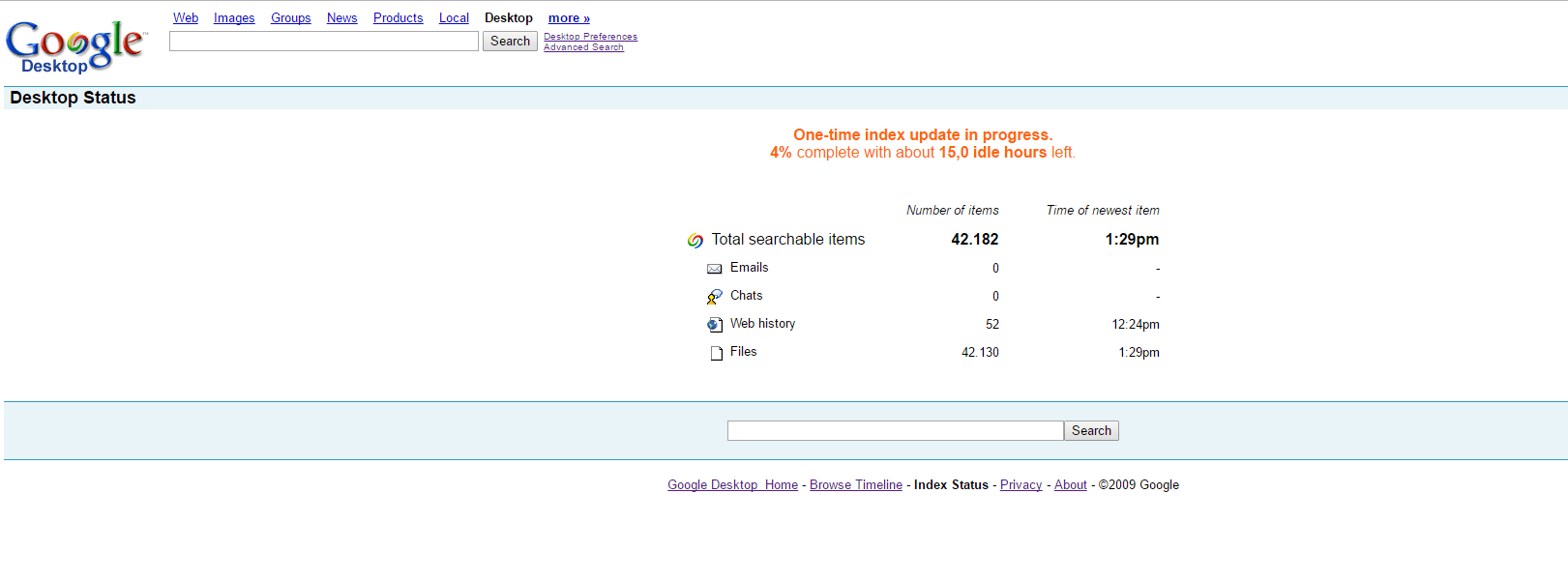
Wenn wir nun den Desktop durchsuchen wollen, brauchen wir einfach nur den Bookmark anklicken, den wir zuvor abgespeichert haben.
Geht es aber noch einfacher? – Ja
Was nun kommt wurde im Chrome Browser eingerichtet, dies sollte jedoch auch in Firefox und anderen Browsern möglich sein.
Im Chrome Browser geht ihr in die Einstellungen und anschließend auf Suchmaschinen Bearbeiten.
Klickt dort auf Hinzufügen.
Könnt ihr euch noch an die URL erinnern, die wir aus der Registry rauskopiert haben?
Diese brauchen wir nun wieder, ihr braucht dazu einfach nur GDS aufrufen und könnt von dort die URL einfach kopieren.
Vermutlich sieht die URL bei euch in etwa so aus:
http://127.0.0.1:4664/search&s=<XYZ>?q=
Natürlich habt ihr statt „<XYZ>“ etwas eigenes dort stehen.
Ihr habt vorhin bei „Suchmaschinen Bearbeiten“ auf „Hinzufügen“ geklickt und seht nun dieses Fenster:

Füllt die Felder aus:
Suchmaschine: Einfach nur den Namen, kann irgendwas sein.
Suchkürzel: Den könnt ihr euch auch aussuchen, sollte jedoch kurz und merkbar sein (im Bild sieht man „desk“ für „Desktop“.
URL: Hier fügt ihr nun die URL ein, die ihr zuvor kopiert habt: http://127.0.0.1:4664/search&s=<XYZ>?q= UND ihr hängt am Schluss noch ein „%s“ (ohne Anführungszeichen) dazu.
Es sollte also so aussehen: http://127.0.0.1:4664/search&s=<XYZ>?q=%s
Speichern nicht vergessen.
Wenn ihr nun in der Adresszeile des Browsers „desk SUCHTEXT“ eingebt dann durchsucht ihr GDS nach den eingegebenen Suchtext.
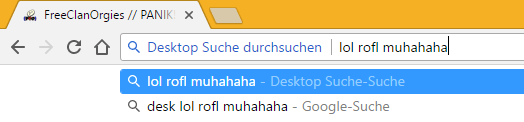
Es sieht nach viel Arbeit aus, ist aber in Wirklichkeit relativ schnell alles eingerichtet, wie man sieht.